在Prometheus监控中,对于采集到服务端的指标,称为metrics数据。
metrics指标为时间序列数据,它们按相同的时序,以时间维度来存储连续数据的集合。
metrics有自定义的一套数据格式,不管对于日常运维管理或者监控开发来说,了解并对其熟练掌握都是非常必要的,本文将对此进行详细介绍。
一. Mtrics组成
每个metrics数据都包含几个部分:指标名称、标签和采样数据。
指标名称
用于描述收集指标的性质,其名称应该具有语义化,可以较直观的表示一个度量的指标。名称格式可包括ASCII字符、数字、下划线和冒号。
如:
node_cpu_seconds_total
node_network_receive_bytes_total标签
时间序列标签为key/value格式,它们给Prometheus数据模型提供了维度,通过标签可以区分不同的实例,
如: node_network_receive_bytes_total{device="eth0"} #表示eth0网卡的数据
通过标签 ,Prometheus可以在不同维度上对一个或一组数据进行查询处理。标签名称由 ASCII 字符,数字,以及下划线组成, 其中 __ 开头属于 Prometheus 保留,标签的值可以是任何 Unicode 字符,支持中文。标签可来自被监控的资源,也可由Prometheus在抓取期间和之后添加。
采样数据
按照某个时序以时间维度采集的数据,其值包含:
一个float64值
一个毫秒级的unix时间戳
二. Metrics格式
结合以上这些元素,Prometheus的时间序列统一使用以下格式来表示。
<metric name>{<label name>=<label value>, ...}
下面为一个node-exporter暴露的数据指标样本:
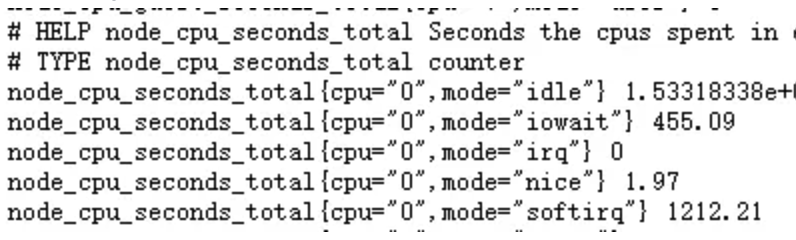
第一个#是指标的说明介绍,第二个# 代表指标的类型,此为必须项且格式固定,TYPE+指标名称+类型。node_cpu_seconds_total为指标名称,{}里面为标签, 它标明了当前指标样本的特征和维度,最后面的数值则是该样本的具体值。
三. Metric类型
Prometheus的时序数据分为Counter(计数器),Gauge(仪表盘),Histogram(直方图),Summary(摘要)四种类型。
Counter类型
counter类型的指标与计数器一样,会按照某个趋势一直变化(一般是增加),我们往往用它记录服务请求总量、错误总数等。
如下图展示就是一个counter类型的metrics数据采集,采集的是Prometheus的接口访问量,可看到数值一直在向上增加。
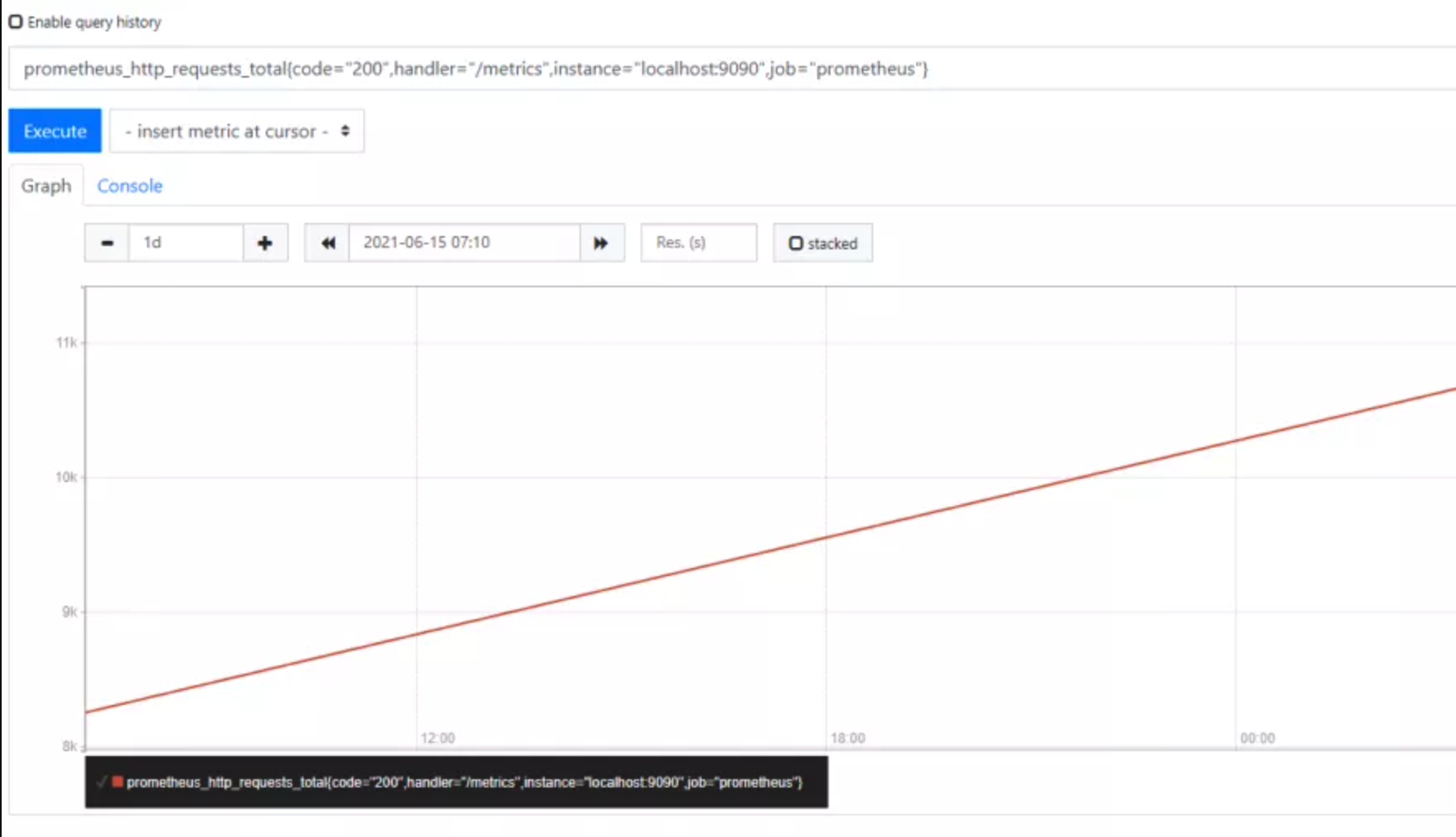
基于counter类型的数据,我们可以清楚某些事件发生的次数,由于数据是以时序的方式进行存储,我们也可以轻松了解该事件产生的速率变化。
例如,通过rate()函数,获取api请求量每分钟的增长率:rate(apiserver_request_total[1m])
Gauge类型
与Counter不同,Gauge类型的指标用于展示瞬时的值,与时间没有关系,可增可减。该类型值可用来记录CPU使用率、内存使用率等参数,用来反映目标在某个时间点的状态。
以下是一个关于内存使用量的数据展示,可以看到每个时间点的数据具有随机性,不与其他数据有关联。
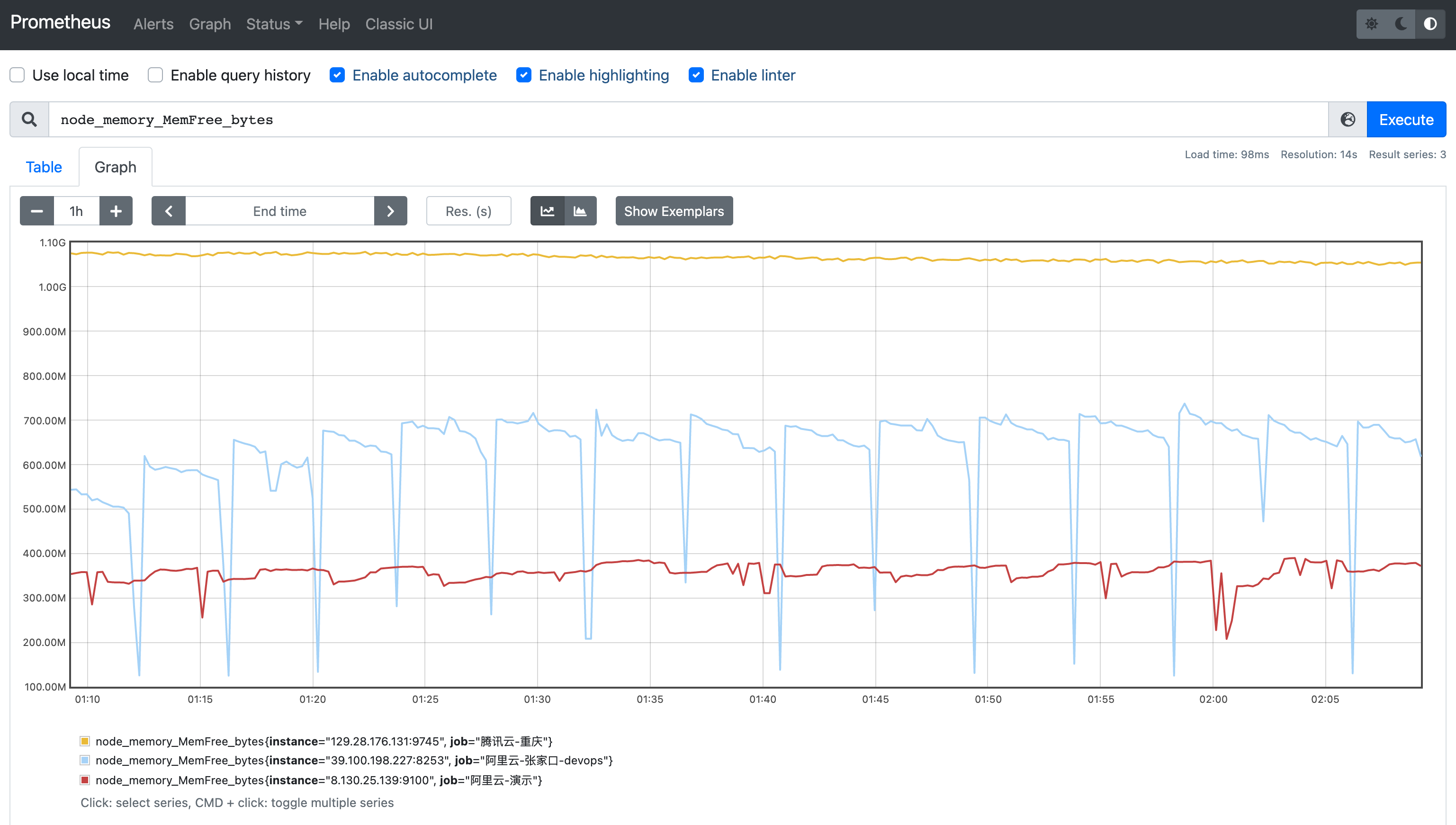
Gauge指标简单且易于理解,对于该类型的指标,我们可以直观的查看目标在当前的状态。
node_memory_MemFree_bytes
Summary和Histogram类型
在大多数情况下,我们可以计算指标某个时间段内的平均值来了解情况,如需要知道每分钟CPU使用率,可通过计算该时间段内采集的数据平均值来获取。
但在某些场景中,这种方式并不合适。假设某个接口一分钟内的请求为1万次,采用平均值的方式计算出响应时间为2s,通过该值我们无法判断是所有请求都不超过2s,还是有部分较高延迟被平均值拉低,该方法缺乏对于全局的观察性。对此,Prometheus通过Summary和Histogram类型来解决这样的问题。
Summary 通过计算分位数(quantile)显示指标结果,可用于统计一段时间内数据采样结果 ,如中位数(quantile=0.5)、9分位数(quantile=0.9)等。
下面是一个Summary类型的指标prometheus_tsdb_wal_fsync_duration_seconds,通过该指标我们可以得知,Prometheus进行wal_fsync操作的数据结果中,50%(quantile=0.5)的耗时小于0.051406522,90%(quantile=0.9)的耗时小于0.053670506。

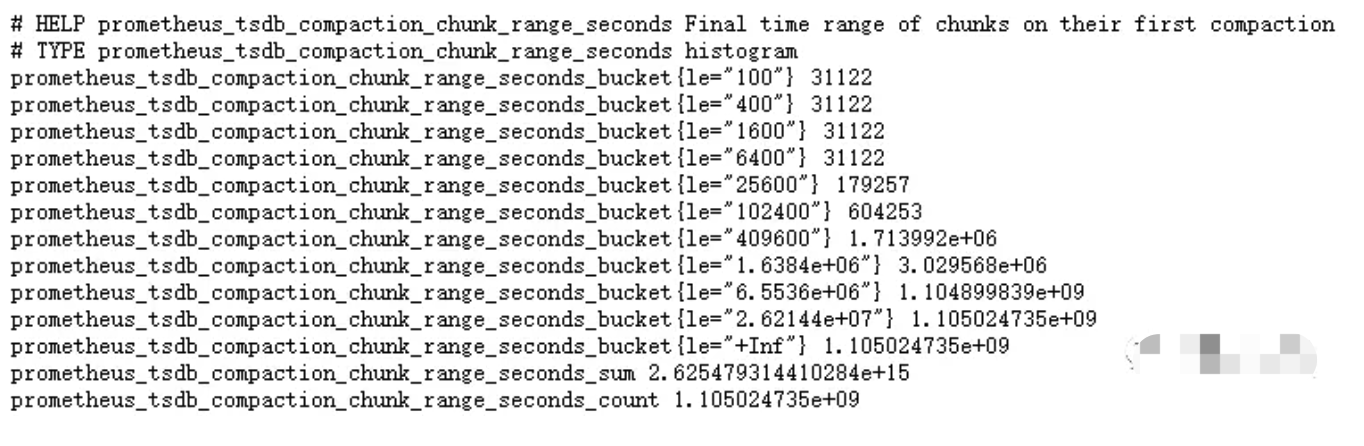
Histogram类型与Summary类型的指标相似之处在于同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义,通常它采集的数据展示为直方图。
Histogram可用于请求耗时、响应时间等数据的统计,例如指标prometheus_tsdb_compaction_chunk_range_bucket即为Histogram类型。