在上篇的文章中,我们通过Grafana实现了监控可视化。而对于运维监控而言,除了监控展示以外,另一个重要的需求无疑就是告警了。良好的告警可以帮助运维人员及时的发现问题,处理问题并防范于未然,是运维工作中不可或缺的重要手段。
在Prometheus的架构中,告警功能由Prometheus Server和Alertmanager 协同完成,Prometheus Server负责收集目标实例的指标,定义告警规则以及产生警报,并将相关的警报信息发送到Alertmanager。
Alertmanager则负责对告警信息进行管理 ,根据配置的接收人信息,将告警发送到对应的接收人与介质 。
一. 添加告警规则
告警规则配置在独立的文件中,文件格式为yml,并在prometheus.yml文件的rule_files模块中进行引用。如下
rule_files:
- "/etc/prometheus/rules/myrules.yml"引用的文件路径支持正则表达式方式,如果有多个文件时,可以用下列的方式匹配
rule_files:
- "/etc/prometheus/rules/*.yml"
- "/data/prometheus/rules/prd-*.yml"默认情况下,Prometheus会每隔一分钟对这些告警规则进行计算,如果用户想定义自己的告警计算周期,可在global 模块中配置evaluation_interval参数来控制。
global:
evaluation_interval: 15s在告警规则文件中, 可以将一组相关的规则设置定义在一个group下,在每一个group中我们可以定义多个告警规则。
如下是一条标准的告警规则,用于检测实例状态是否正常。
groups:
- name: node_alert
rules:
- alert: node_down
expr: up{job="node-exporter"} != 1
for: 1m
labels:
level: critical
annotations:
description: "The node is Down more than 1 minute!"
summary: "The node is down"一条告警规则由以下几部分组成:
- alert:告警规则的名称,在每一个group中,规则名称必须是唯一的。
- expr:基于PromQL表达式配置的规则条件,用于计算相关的时间序列指标是否满足规则。
- for :评估等待时间,可选参数。当相关指标触发规则后,在for定义的时间区间内该规则会处于Pending状态,在达到该时间后规则状态变成Firing,并发送告警信息到Alertmanager。
- labels:自定义标签, 允许用户指定要添加到告警信息上的一组附加标签。
- annotations: 用于指定一组附加信息,如用于描述告警的信息文字等,本示例中 summary用于描述主要信息,description用于描述详细的告警内容。
二. 使用模板
模板(template)是一种在警报中使用时间序列数据的标签和值的方法,可用于告警中的注解和标签。模板使用标准的Go模板语法,并暴露一些包含时间序列的标签和值的变量。
通过
{{ $lable.<lablename>}}
变量可以访问当前告警实例中指定标签的值,
{{ $value }}
则可以获取当前PromQL表达式计算的样本值。
# To insert a firing element's label values:
{{ $labels.<labelname> }}
# To insert the numeric expression value of the firing element:
{{ $value }}在实际使用中,可以通过模板的方式优化summary与description内容的可读性。比如,在描述中插入了实例信息以及PromQL表达式计算的样本值。 如下:
groups:
- name: node_alert
rules:
- alert: cpu_alert
expr: 100 -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)* 100 > 85
for: 5m
labels:
level: warning
annotations:
description: "instance: {{ $labels.instance }} ,cpu usage is too high ! value: {{$value}}"
summary: "cpu usage is too high"三. 规则应用
配置好规则文件后,可以使用 curl -X POST http://localhost:9090/-/reload 或者重启Prometheus的方式让规则更新。 当顺利加载规则后,可以在Prometheus的“Status”- “Rules”页面查看到相关的规则状态信息。
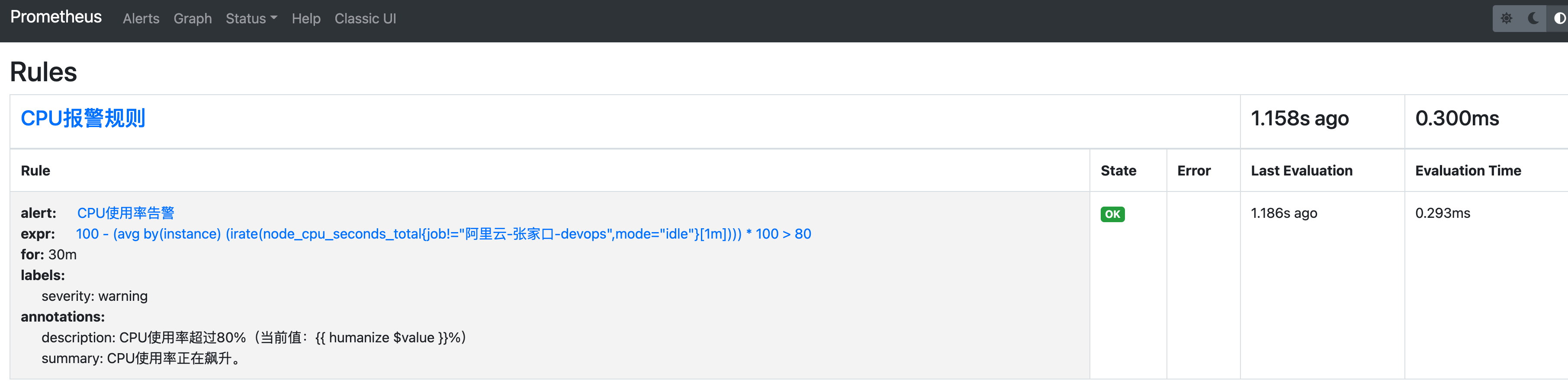
当告警规则生效后,可以在Alerts页面查看警报状态。
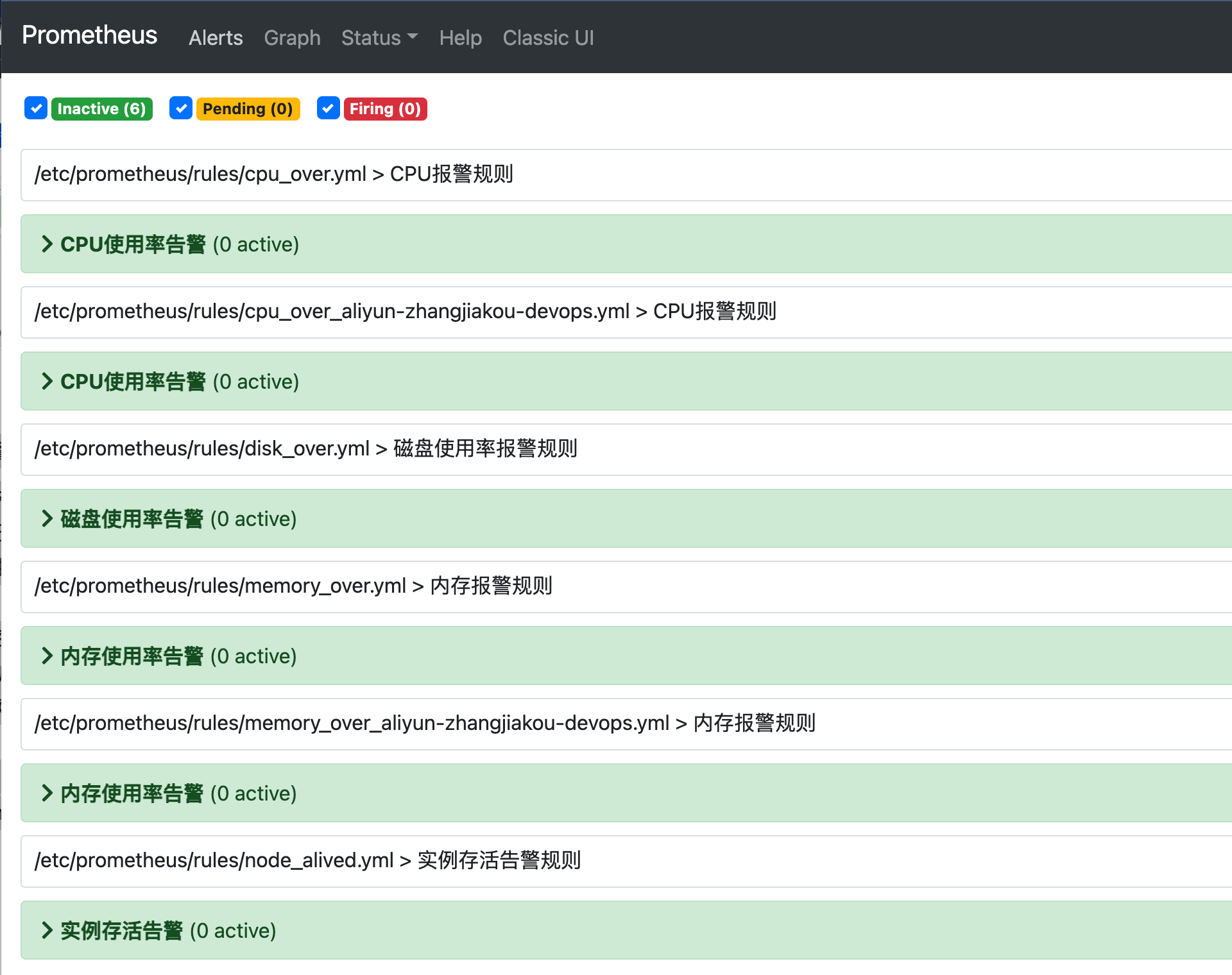
四. 警报状态
Prometheus的警报有如下几种状态:
- inactive :警报未被触发。
- Pending:警报已被触发,但还未满足for参数定义的持续时间。
- Firing:警报被触发警,并满足for定义的持续时间的
告警规则的状态变化如下所示,默认状态为inactive,当规则被触发后将变为Pending,在达到持续时间后变成Firing状态。如果配置的规则没有for子句,那么当规则触发时,警报会自动从inactive转换为Firing,而没有任何的等待周期。
如果配置了Alertmanager的地址,当警报状态为Firing时,Prometheus会将相关的告警信息转发到Alertmanager,并由其进行告警信息的发送。在恢复正常后,警报状态重新变回inactive。
结语
本文介绍了关于Prometheus告警规则的配置,到目前为止,我们只能通过Prometheus UI查看当前警报的活动状态。 Prometheus自身并不提供告警发送功能,其需要与Alertmanager结合,才能实现警报的管理与发送。 限制篇幅原因,Alertmanager的讲解放到下一篇文章中介绍。