Amazon S3 Files 是什么?
Amazon S3 Files 是 AWS 在 2026 年 4 月发布的 S3 新功能:它可以把 S3 bucket 以文件系统的方式访问。 也就是说,你的数据仍然存放在 S3 里,但 EC2、EKS、ECS、Lambda 等计算资源可以像访问普通文件系统一样访问这些对象数据。 AWS 官方描述是:S3 Files 提供 shared file system,直接连接 AWS compute 和 S3 数据,并提供 file system semantics 和低延迟访问。
以前: Application → S3 API → S3 Object
现在使用 S3 Files: Application → File System Interface → S3 Data
应用看到的是:
/mnt/s3files/report.csv
/mnt/s3files/images/a.png
/mnt/s3files/logs/app.log但底层实际还是:
s3://bucket/report.csv
s3://bucket/images/a.png
s3://bucket/logs/app.log它解决什么问题?
S3 Files 的作用就是让这些应用可以用文件系统方式访问 S3 数据,不需要把 S3 数据先复制到 EFS、FSx、EBS 或本地磁盘。 AWS 官方博客也说明,S3 Files 可以让 S3 bucket 作为 file system 被访问,文件系统变化会自动反映到 S3 bucket 中。
核心功能
S3 Files 让对象数据表现得像文件和目录。应用可以执行类似:
- ls
- cd
- cat
- open()
- read()
- write()
这对传统应用迁移、AI 数据集访问、日志分析、批处理任务很有用。
不需要复制数据
数据仍然留在 S3,不需要同步一份到 EFS 或 FSx。这样可以减少数据孤岛和重复存储成本。AWS 官方明确说,S3 Files 让应用、agent 和团队可以直接以文件方式访问 S3 数据,而不需要在 object storage 和 file system storage 之间来回复制。
面向 AWS compute
S3 Files 主要是给 AWS 内部计算资源使用,例如 EC2、EKS、ECS、Lambda 等访问 S3 数据。AWS “What’s New” 中说明它可以把 AWS compute resource 直接连接到 S3 数据。
和普通 S3 有什么区别?
| 对比项 | 普通 S3 | S3 Files |
|---|---|---|
| 存储模型 | Object Storage | S3 数据的文件系统访问层 |
| 访问方式 | S3 API / SDK / CLI | 文件系统接口 |
| 应用改造 | 应用通常要支持 S3 API | 应用可以像读写本地文件一样访问 |
| 典型路径 | s3://bucket/key | /mnt/xxx/file |
| 适合场景 | 云原生对象存储、备份、静态资源、日志 | 传统文件应用、AI/ML、数据处理、共享文件访问 |
典型使用场景
S3 Files 适合:
AI/ML 数据集访问
训练任务需要通过文件路径读取大量数据,但数据实际存在 S3。
传统应用迁移到 AWS
老应用只认识 /data/file.txt,不认识 s3://bucket/file.txt。
EKS / ECS 工作负载访问共享数据
多个容器或任务需要共享访问 S3 中的数据。
数据分析和批处理
脚本、ETL、Spark 周边工具需要像处理文件夹一样处理 S3 数据。
减少 EFS/FSx 中转层
如果只是为了让程序通过文件路径访问 S3,S3 Files 可以减少额外的数据复制。
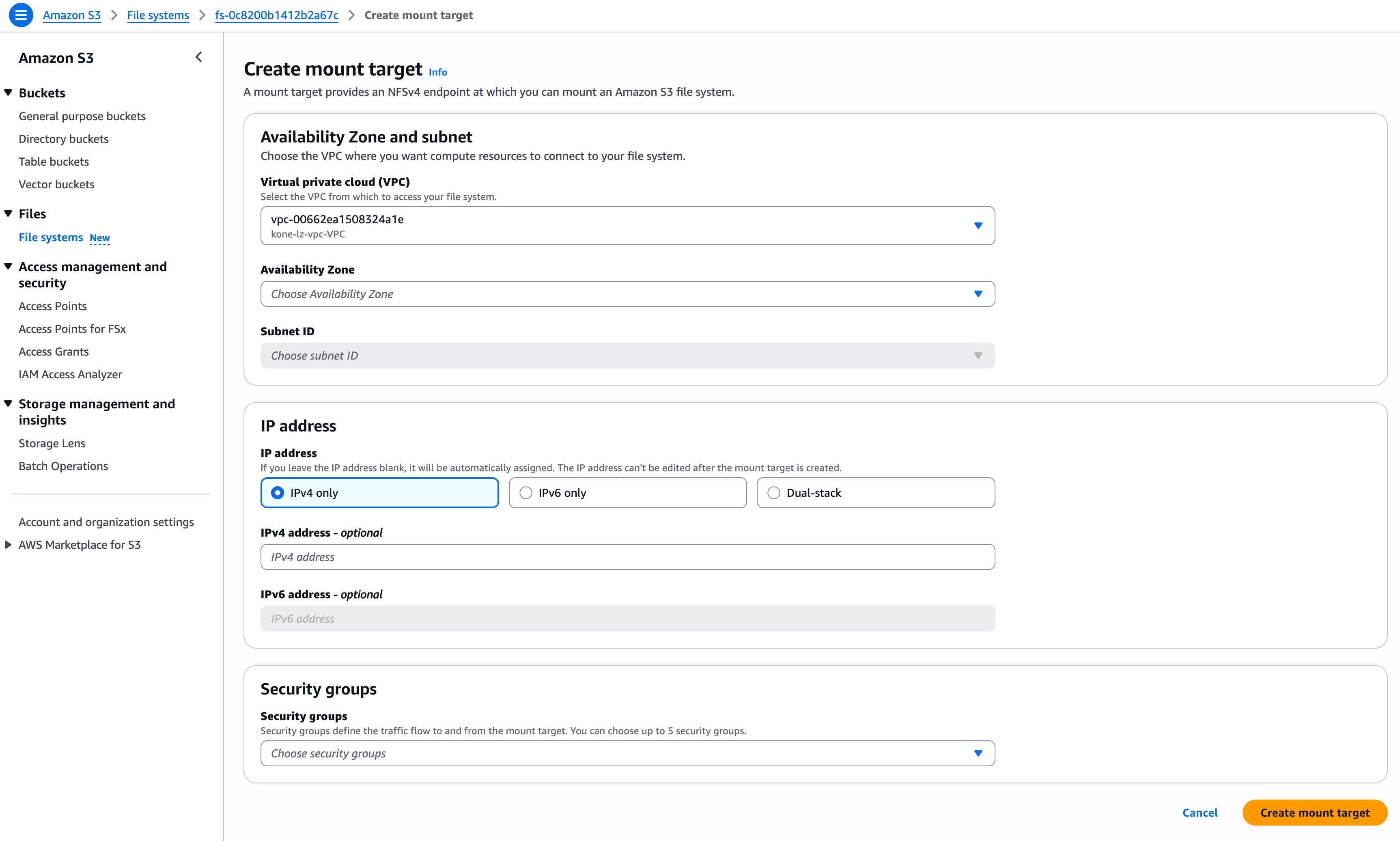
截图
创建文件系统 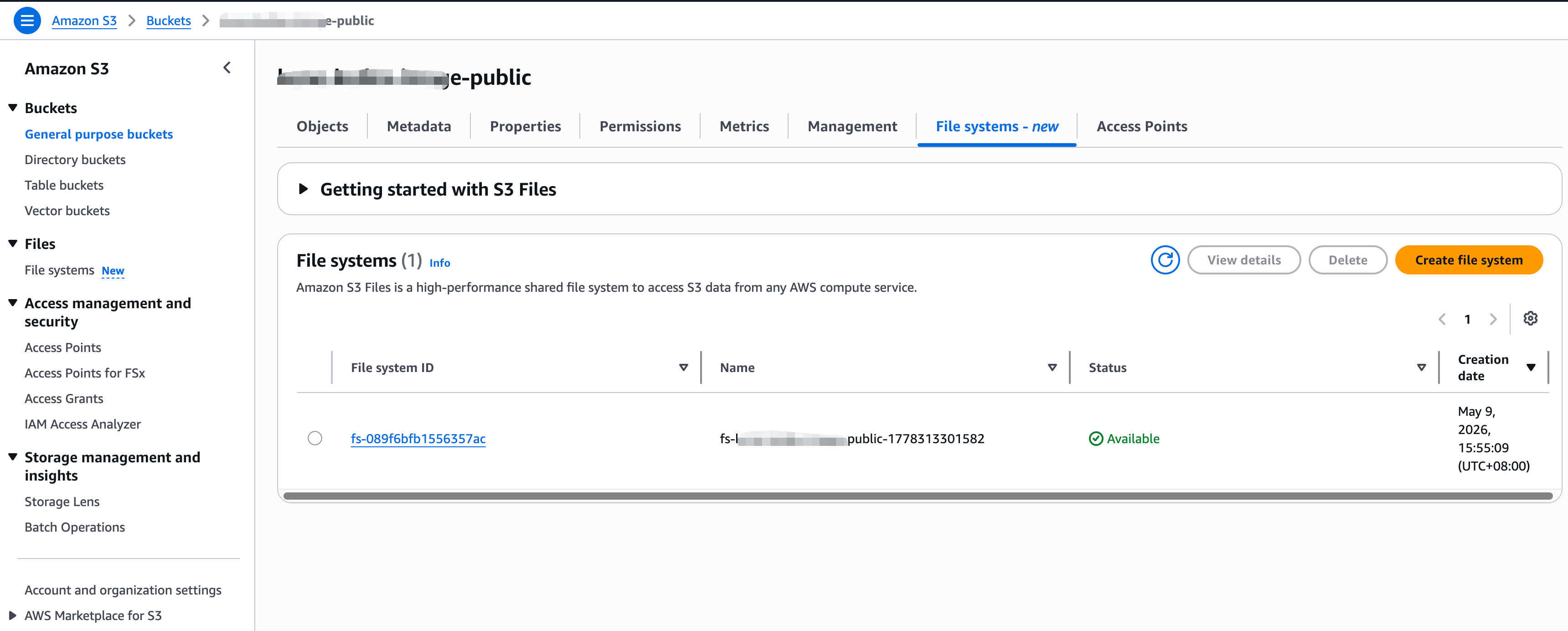
查看文件系统 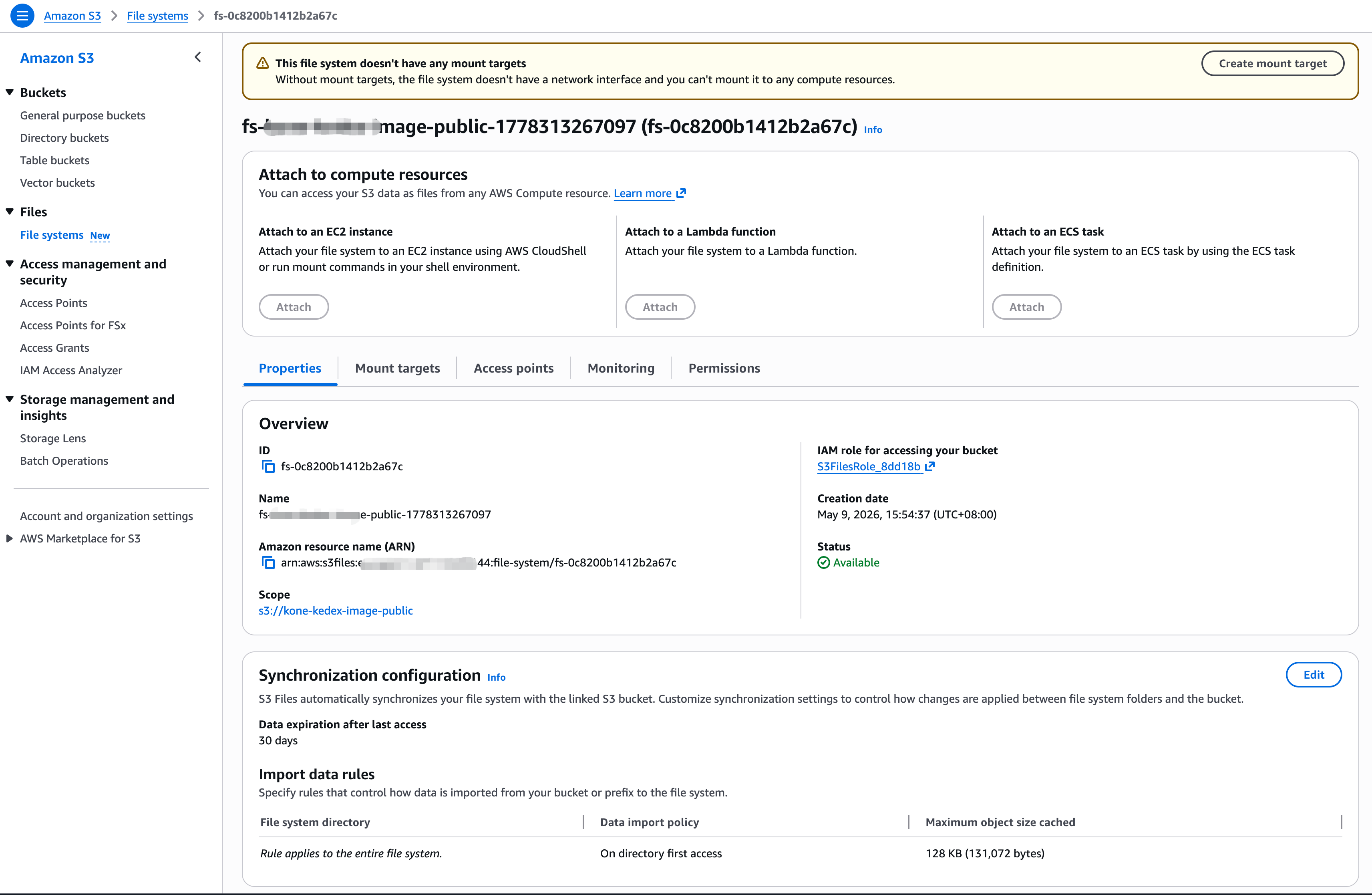
基于文件系统创建挂载点